 Gerald Haslhofer
Gerald Haslhofer 
The goal of this exercise was to explore the most recent advances in natural language processing and apply it to a real-world problem:
When having two different collections of articles denoted by their headlines, which collection should a new, unseen article be added to?
Secondarily, given two to-do lists, which list should a new to-do item be added to?
The solution applied here attempts to create a similarity measure to pick the top-n most similar articles based on semantic similarity. It leverages the state-of-the art Transformer based model - BERT.
Step 0: Understand what BERT is
See the previous blog post on NLP, section “Transformers”.
Step 1: Data science environment setup on a Surface Book
I opted for the Surface Book laptop with a reasonable GPU. Let’s start with setting up the environment with Python, and a great editor (Visual Studio Code).
Understand Visual Studio Editor and Python
Introduction to Visual Studio Code and Python
Downloads
- Visual Studio Code download
- Python installer for Python 3.8.1. Make sure that environment variables are set
- Leverage Anaconda distribution
- Create directory, start Visual Studio Code (
cd dir; code .) - Select environment: CTRL+SHIFT+P, “Python: Select Interpreter”
- Create a terminal window: CTRL+SHIFT+P, “Terminal: Create New Integrated Terminal”
- Install tensorflow GPU (with Conda). New Command Window.
conda install tensorflow-gpu(Conda is preinstalled)
Conda and Pip coexistence: https://www.anaconda.com/using-pip-in-a-conda-environment/
- Create new environment with Conda so you control the right version of e.g. Tensorflow (Bert-as-a-service does not work with Tensorflow 2.0)
conda create environname
conda activate environname
Make sure the GPU works for Tensorflow
# verify GPU availability
import tensorflow as tf
device_name = tf.test.gpu_device_name()
if device_name != '/device:GPU:0':
raise SystemError('GPU device not found')
print('Found GPU at: {}'.format(device_name))
Step 2: Choose tutorial to get started
Potential tutorials, ultimately chose Bert-as-a-service as it allowed the most straightforward experiments
- Tutorial 1: Bert Explained
- Tutorial 2: Intent classification
- Tutorial 3: Huggingface Transformers
- Tutorial 4: BERT word embedding tutorial
- Tutorial 6: BERT as service Our choice.
Step 3: set up Bert-as-a-service
https://github.com/hanxiao/bert-as-service
pip install bert-serving-server # server
pip install bert-serving-client # client, independent of `bert-serving-server`
Download BERT model from Google.
Download location of original model
and extracted it to
C:\Users\gerhas\code\python\uncased_L-12_H-768_A-12
Start the BERT server component
bert-serving-start -model_dir c:\users\gerhas\code\python\uncased_L-12_H-768_A-12 -num_worker=4
Step 4: Create sample dataset
We create two collections, and add headlines to each one of them.
I chose two distinct sets of headlines: one set with articles about machine learning, one set with articles about general self-improvement articles, sourced from Medium.com and other sites.
Sample collection #I: AI related topics
- 2020 NLP wish lists, HuggingFace + fastai, NeurIPS 2019, GPT-2 things, Machine Learning Interviews Revue
- Google Brain’s AI achieves state-of-the-art text summarization performance
- Image Segmentation: Kaggle experience
- Article: TensorFlow 2 Tutorial: Get Started in Deep Learning With tf.keras
- Examining BERT’s raw embeddings
- Eight Surprising Predictions for AI in 2020.
- Recent Advancements in NLP (1/2)
Sample collection #II: Self-improvement and general interest books
- 7 Reasons Why Smart, Hardworking People Don’t Become Successful by Melissa Chu
- The Secret To Being Loved The Way You Dream Of
- The World Beyond Your Head’ by Matthew B. Crawford
- Become What You Are by Alan Watts
- The Sense of Style’ by Stephen Pinker
- The Storm Before the Storm’ by Mike Duncan
- The 1 Thing I Did That Changed My Entire Life For The Better
- The Five Qualities You Need in a Partner
Step 5: Writing the code
The code is a simple adaptation of the sample code of the Bert-as-service manual.
from bert_serving.client import BertClient
import numpy as np
prefix_q = '##### **Q:** '
with open('C:\\Users\\gerhas\\code\\BERT-experiments\\collections.txt') as fp:
questions_raw = [v.replace(prefix_q, '').strip() for v in fp if v.strip() and v.startswith(prefix_q)]
print('%d titles of collections loaded, avg. len of %d' % (len(questions_raw), np.mean([len(d.split()) for d in questions_raw])))
questions_cat = [v[:4] for v in questions_raw]
questions = [v[5:] for v in questions_raw]
count = len(questions)
bc = BertClient()
doc_vecs = bc.encode(questions)
while True:
query = input('Enter title of new article:')
query_vec = bc.encode([query])[0]
# compute normalized dot product as score
score = np.sum(query_vec * doc_vecs, axis=1) / np.linalg.norm(doc_vecs, axis=1)
topk_idx = np.argsort(score)[::-1][:count]
count = 1
for idx in topk_idx:
print('> %s\t%s\t%s\t%s' % (count, score[idx], questions_cat[idx], questions[idx]))
count+=1
print("end")
Step 6: Running the model
Now to the exciting part: let’s enter a new title, and see a ranked list of most to least similar articles in the base dataset. We can use this ranking to determine whether the new article should be added to collection #1 (AI articles), or collection #2 (General Interest).
Experiment 1: New article named “neural networks”
We have a new article called “neural networks”. Which collection should it belong to?
The results are stunning: entering “neural networks” leads to all AI related articles being ranked higher than all of the other general interest ones. Look at the ranked list here:

Note that none of the existing articles had “neural networks” in them literally, so traditional TFIDF approaches would not have worked due to the small text corpus being available.
Experiment 2: New article named “How to grow your career and prosper”
In this experiment we chose a general purpose title, which clearly had nothing to do with AI.
The results are again very compelling: The top 4 articles based on similarity with the term are in the general purpose category. Look at the ranked list here:

Experiment 3: ToDo lists”
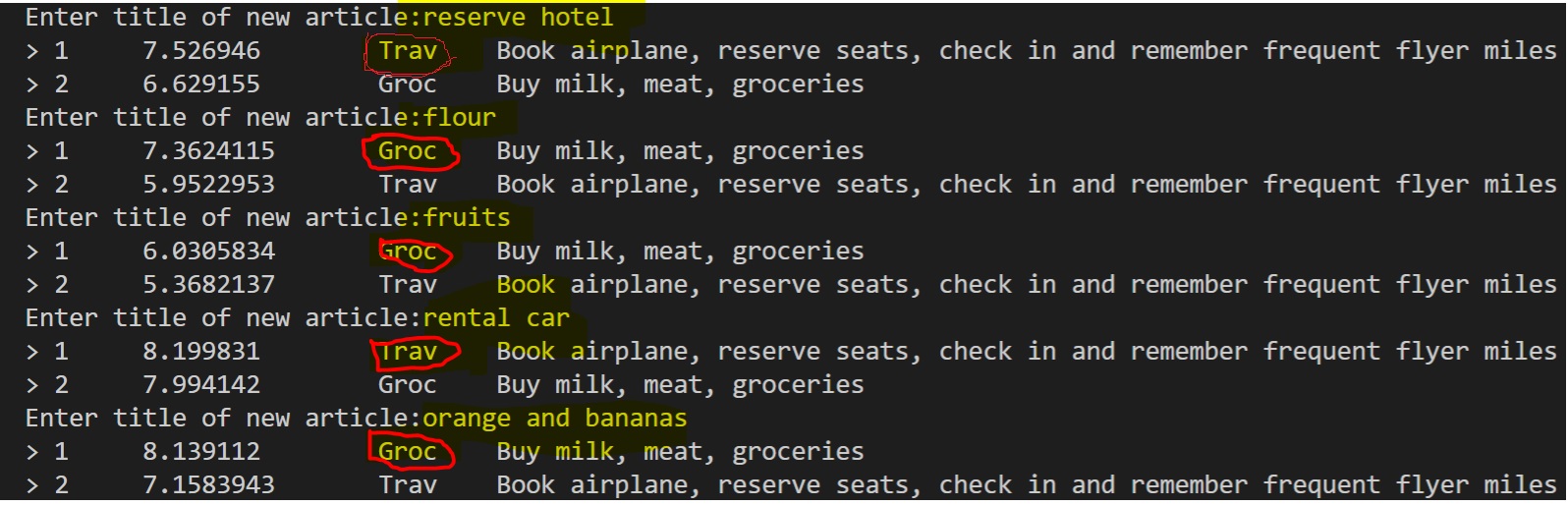
I create two todo lists -
#1 - One around shopping with the content of “Buy milk, meat, groceries”
#2 One with travel activities “Book airplane, reserve seats, check in and remember frequent flyer miles”
When entering new items, the system consistently chooses the right list to add the new item to. E.g. when selecting “flour” the system ranks the “groceries” list higher, when selecting “rental car”, the system chooses “Travel”.
Bottom line: BERT appears to be a very promising approach!
Updates
https://www.python.org/downloads/release/python-376/
https://automaticaddison.com/how-to-install-tensorflow-2-on-windows-10/
conda create -n mypython3 python=3 conda activate mypython3 python -m pip install bert-serving-server
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py python get-pip.py virtualenv –system-site-packages -p python ./venv .\venv\Scripts\activate
Appendix
sentence embedding
Quick Semantic Search using Siamese-BERT Networks” by Aneesha Bakharia https://link.medium.com/kX6QF9oqG3
#Deploying Python service to Azure
Django, Flask
https://azure.microsoft.com/en-us/develop/python/ https://www.youtube.com/watch?time_continue=837&v=0Bk0dw2Ktbg&feature=emb_logo
https://cloudblogs.microsoft.com/opensource/2020/01/21/microsoft-onnx-open-source-optimizations-transformer-inference-gpu-cpu/
https://github.com/onnx/tutorials/blob/master/tutorials/Inference-TensorFlow-Bert-Model-for-High-Performance-in-ONNX-Runtime.ipynb
 Natural language processing - Introduction
Natural language processing - Introduction